Social development programs are complex. To promote social development wisely, decision-makers need many different kinds of information from different kinds of studies and reports. The basic scheme for monitoring and evaluation of social programs recognizes these different requirements (See Figure 1). Studies that report on the application of financial, human and material resources are essential to monitoring implementation, as are studies of program activities and outputs. Process Evaluations and Operational Evaluations – providing information on these inputs, activities and outputs – are important for improving program implementation, and critical to understand why a program was or wasn’t effective. Without implementation, no program can achieve its goals. But without measuring the impact of a program, improved implementation has no purpose – in fact, it may be wasteful or harmful. Thus, another kind of study – impact evaluation – is necessary to find out whether or not a program is having the desired effects.
Evaluations can be generally classified according to their focus and objectives. Many evaluations are concerned with reviewing an entire portfolio of projects in a country or a particular sector and require evidence on the individual and joint effects of the projects. Other evaluations are concerned with internal performance, such as adherence to strategies or efficiency of administration. Evaluations of specific social development projects and programs tend to fall into the following categories:
- Needs Assessment – answers questions about the social conditions a program is intended to address and the need for the program.
- Monitoring Implementation – verifies the use of inputs in program activities according to the program design or approved adjustments, including audits.
- Process & Operational Evaluation – investigates the degree to which the program was implemented as designed and was completed on time and within budget, with the aim of improving implementation
- Outcome evaluation – documents the status of people after participating in a program (i.e. measuring gross changes).
- Impact Evaluation – documents the extent to which changes in the wellbeing of the target population can be attributed to the particular program (measuring net changes).
Of these five categories, our investigation has found substantial resources are spent on the first four of these categories of evaluations, but insufficient effort is going toward producing good quality impact evaluations. In developing countries, resources for social development programs are often overstretched such that information gathering activities are neglected. In countries with effective information gathering, most of these resources are directed toward monitoring the use of funds, the deployment and management of personnel, and the production of outputs and services. By contrast, relatively little is spent to rigorously assess whether programs are having the desired impact above and beyond what would occur without them.
Among bilateral and multilateral development assistance agencies, a share of program funds are generally dedicated to monitoring implementation and disbursement, but studies that look to these data sources for learning about program effectiveness are regularly disappointed. The kinds of data collected do not lend themselves to measuring net impact of programs.
In addition to evaluations of specific social development programs, governments and agencies regularly evaluate their own performance through independent studies of all their programs in a given country, region or sector, or of their policies, operations and strategies (See "Selected Organizational Evaluations", Figure 1 in PDF). While evaluating specific social programs is generally the responsibility of operational and research departments, independent Evaluation Departments in these agencies are primarily responsible for what might be termed "organizational evaluations" – analyzing processes and operations, program implementation, and policies and strategies. Much progress has been made to make these Evaluation Departments more independent, effective and useful to their agencies through internal reforms and through coordinated efforts among bilateral agencies, such as the Development Assistance Committee's Evaluation Network, and including the multilateral development banks through the DAC/MDB Joint Venture on Managing for Development Results.
Despite this progress, these Evaluation Departments are constrained in areas where good impact evaluations are lacking. Without selective impact evaluations, Evaluation Departments have difficulty drawing conclusions about aid effectiveness. And yet, the independence of these departments bars them from collaborating with staff in the project preparation and implementation phases – a necessary requirement for designing effective impact evaluations. The core work of these Evaluation Departments – providing independent assessments of the performance of their organizations and developing recommendations – would benefit if more good quality impact evaluations were undertaken so that they could draw inferences and conclusions about their agencies’ resource allocation decisions, strategies, priorities, effectiveness and efficiency. In this way, more and better impact evaluations would complement and strengthen accountability among bilateral agencies and multilateral development banks.
The need for good impact evaluations is increasing as a result of current trends in international development assistance away from funding tied to specific projects and toward "budget support", sector-wide approaches, "Poverty Reduction Strategies", "Indefinite Quantity Contracts" at USAID and similar initiatives at other bilateral agencies, and a wide range of other efforts aimed at reinforcing developing countries as “owners” of their domestic social development agendas. Only through selective use of impact evaluation will it be possible for these broad programs to determine whether resources are flowing toward effective uses. Without this attention to measuring the impact of social development programs, the essential learning of what kinds of programs do and do not work will not take place.
Very few good impact evaluations are carried out
Given that many projects can learn from a single well-done evaluation, it is not necessary for all programs to include such studies. However, given the knowledge gaps identified above, the numbers of impact evaluations actually being carried out is clearly too low. For example,
- A systematic review of UNICEF reports found that 44 out of 456 were impact evaluations. The review estimated that 15% of all UNICEF reports included impact assessments, but noted that "[m]any evaluations were unable to properly assess impact because of methodological shortcomings" (Victora 1995).
- Out of 139 studies conducted by Chile's Budget Department between 1997 and 2002, only 6 were impact evaluations (Marcel 2002).
An informal survey of international development organizations also demonstrates that few impact evaluations are undertaken. At the Inter-American Development Bank, out of 593 projects that were active as of July 2004, only 97 reported they had collected data on beneficiaries and, of these, only 18 had data on non-participants – information that is necessary, though not sufficient, for evaluating impact. Similar results can be found at most other regional development banks and bilateral agencies.
The World Bank may be doing better of late. In 1998, it reported that only 5% of its projects had associated impact evaluations, while in 2000, this share had increased to 10%. (World Bank 1999, World Bank 2001). The World Bank’s Research Department is currently engaged in an initiative to make impact evaluation a more systematic endeavor within the bank, focused around six thematic areas (See Box 2). Impact evaluations that the World Bank has already completed or reviewed have already informed policy toward social funds, conditional cash transfers and educational decentralization. Much less is apparently known about other questions confronting the World Bank in nutrition, health sector reform, and attention to indigenous groups. Studies are also geographically concentrated in certain regions, most notably in Latin America and to a lesser extent in Sub-Saharan Africa.
| Box 2: The Development IMpact Evaluation (DIME) Initiative
The World Bank identified several bottlenecks that limit its ability to conduct impact evaluations at the necessary scale and with the needed continuity: insufficient resources, inadequate incentives, and, in some cases, lack of knowledge and understanding. To address these bottlenecks, the Development IMpact Evaluation (DIME) Initiative is a Bank-wide collaborative effort under the leadership of the Bank’s Chief Economist that is oriented at: (1) increasing the number of Bank projects with impact evaluation components, particularly in strategic areas and themes; (2) increasing the ability of staff to design and carry out such evaluations, and (3) building a process of systematic learning on effective development interventions based on lessons learned from completed evaluations. The Bank identified five thematic areas to concentrate its current efforts at impact evaluation – school based management and community participation in education; information for accountability in education; Teacher contracting; conditional cash transfer programs to improve education outcomes; and slum upgrading programs. Additional themes are under consideration. DIME envisions working in partnership with its member countries to identify opportunities for learning from impact evaluations that would be given technical support. It aims to improve internal incentives to undertake more systematic development impact evaluations by explicating recognizing these studies as a valued product in their own right. DIME is a prominent illustration of the ways that some international agencies and governmental ministries are trying to build a “Culture of Evaluation” – making the conduct of selective and strategic impact evaluations and the use of impact evaluation findings an integral part of management and decision-making. Source: World Bank. 2005. "The Development IMpact Evaluation (DIME) Initiative: Coordinating Impact Evaluation Work At The World Bank", Draft Report, World Bank: Washington, DC. And interviews with Francois Bourguignon, Ariel Fiszbein, Paul Gertler, and Carolie Gevers. |
A further indication that too few impact evaluations are being conducted in sufficient numbers, despite being asked for and financed, comes from the shortcomings listed in evaluation reports themselves. The following selection from such studies does not represent a systematic survey, but is quite recognizable for anyone familiar with reading evaluation reports (See the appendix for further examples).
- "… this review revealed that, with the exception of Jalan and Glinskaya, none of the studies could qualify as true impact evaluations." [An evaluation of a US$1.3 billion primary education program in India with support from the World Bank, the European Commission, DFID, UNICEF and the Dutch government].
- "… there is no proper baseline survey with which the present-day economic situation of the trained farm women and their families can be compared." [A DANIDA review of four training projects for farm women].
- "The original plan to collect pre- and post-quantitative data to measure the change in learners’ reading, writing and numeracy skills over the course of the project proved impossible for a variety of reasons" [an NGO program to use computer technology in literacy training for adults in Zambia and India].
Many impact evaluations have flawed designs
Even when impact evaluations are carried out, they are often too flawed to provide reliable information. Some of the most common ways to estimate the impact of a program are to:
- compare outcomes before and after a program is implemented and
- compare outcomes in areas that receive a program with those that do not receive a program.
Unfortunately, both of these approaches can be seriously misleading. First, showing an improvement by comparing outcomes before and after a program has been introduced may tell us very little about the program’s impact (See Box 3). Many things change at the same time that a project is implemented, so without further information, it is not valid to assume that observed outcomes are due to the project.
Second, a comparison of changes in communities (or people) who receive program benefits with those who do not will be misleading whenever systematic differences between the two groups are ignored. In fact, many studies reach erroneous conclusions because they either ignore such systematic differences or cannot properly account for their confounding effects. Such systematic differences are common in social programs because in many cases the programs are implemented in communities where they are expected to have the best chances of success, while in other cases, program beneficiaries “self-select” into the programs.
| Box 3. “Before and After” Studies Can Be Misleading
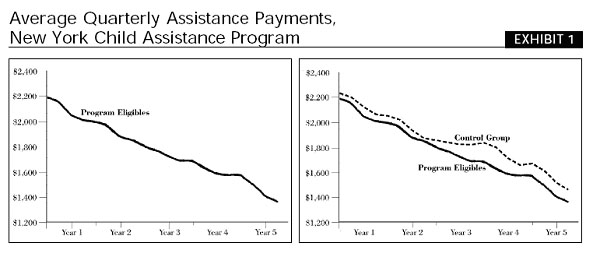
"Exhibit 1 shows how failure to take into account the temporary nature of the need for assistance can create a misleading impression of program effectiveness. The left hand panel of the exhibit shows the time path of quarterly public assistance benefits to a sample of AFDC [Aid for Families with Dependent Children] recipients who were eligible for a program designed to help them become employed and leave the welfare rolls. The steep downward trend in assistance payments would appear to indicate that the program was quite effective. This is in fact the type of “evidence” that is frequently used to demonstrate program effectiveness in the legislative process and in the popular media. As shown in the panel on the right, however, the decline in benefits was nearly as steep for a control group of program eligibles who were excluded from the program, as part of a social experiment. This comparison demonstrates that most of the decline in benefits experienced by the participant group was the result of normal turnover of the welfare rolls, as recipients’ circumstances improved and they were able to leave welfare. Attributing the effects of this turnover to the program greatly overstates its effectiveness."
Source: Orr, Larry L. 1996. “Why Experiment? The Rationale and History of Social Experiments”, Part I of Social Experimentation: Evaluating Public Programs With Experimental Methods. U.S. Department of Health and Human Services. Washington, DC. http://aspe.os.dhhs.gov/hsp/qeval/part1.pdf |
A prominent example of the first kind of systematic bias is a large World Bank-financed initiative on education in India (DPEP) that was placed in areas where the potential for improvement was judged to be greatest. As a result, any comparison of target and non-target areas would be unable to tell whether improvements in primary schooling were due to the program or due to the better institutional conditions and implementation capacities of the beneficiary communities.
The second kind of bias, "self-selection", occurs whenever the people who choose to participate in a program systematically differ from those who decide not to participate. This can occur when people with greater resources, motivation, or abilities seek out assistance from new programs. In such cases, it is difficult to know whether improved outcomes are due to these unobserved characteristics of the individuals who choose to participate or whether it can be attributed to the intervention.
For example, it is common to find studies that show students in private schools perform better than those in public schools. However, the students in private schools are there as a result of choices made by families. Even after controlling for socioeconomic factors, children who attend private schools are likely to come from families who are more committed to education and more motivated. To disentangle the effect of the schools from the effects of these unobservable characteristics is exceedingly difficult unless random assignment is used.[i]
When the selection of beneficiaries is influenced by any of these patterns, it is difficult to know (and usually impossible to test) whether statistical controls for observable difference will fully account for the potential bias. In fact, both the extent and the direction of the bias may be unknown and numerous studies have shown how prevalent such bias can be (Glazerman and Levy 2003, Lalonde 1986).
To avoid these problems it is usually necessary to build an evaluation into the design of a program from the start so that appropriate control groups can be identified. The most straightforward and the most reliable way to generate appropriate control groups is to use random assignment – that is, randomly choosing which individuals, families or communities will be offered a program and which ones will not. Where this method can be applied, it has been shown to be the most effective way to assure that impact measurements are not confounded by systematic differences between beneficiary and control groups (See Box 4).
[i] One randomized study in Chicago found that students who were randomly given the option of choosing their school performed better than those who remained in their assigned schools; however, the entire effect was due to the higher level of motivation among the children (and their families) who decided to change schools. A study based on non-randomized methods might have erroneously attributed the difference in performance to the quality of the schools that were chosen (Cullen, Jacob and Levitt 2002).
| Box 4. Advantages and Limitations of Random Assignment Studies
The key advantage of random assignment studies is that they can effectively reduce unobserved bias and give greater confidence that the measured impact of a program is attributable to that program and not to some other factor. In general, methods that do not use random assignment can only account for systematic biases that are related to observable differences between treatment and control groups. The exceptions are studies that take advantage of “natural” experiments, such as those using regression discontinuity. To see why this is the case, consider job training programs that were financed by the United States in the 1970s and 1980s. Several studies compared the earnings of job trainees to individuals in the general population with similar characteristics who did not partake in the job training program. These studies were disappointing, finding that job trainees earned less than others with similar characteristics. What these studies could not address is that the individuals who entered these public job training programs had already failed to find work – some unobserved factors accounted both for their need for the program and for their subsequently poorer earnings (See Figure A in PDF). A prospective study that randomly assigned which applicants could participate in the job training program, however, yielded opposite results – finding that job training did lead to improved earnings. The random assignment study was able to reach the correct conclusion because it only compared individuals who would be eligible for the program, thereby eliminating the unobserved differences that skewed the other studies (See Figure B in PDF) The literature that demonstrates how misleading studies can be is extensive and growing. It includes comparisons between studies with and without randomized assignment on topics such as: the impact of neighborhood poverty on individuals (Liebman, Katz and Kling 2004); the effectiveness of training programs (Mathematica 1984; Lalonde 1986; Friedlander and Robins 1995; and Friedlander, Greenberg and Robins 1997); social welfare policy in Sweden (Bratberg et al 2002); welfare, job training, and employment services programs (Glazerman and Levy 2003);conditional cash transfer programs (Diaz and Hanshu 2004); and improving test scores and reducing dropout rates (Wilde and Hollister 2002; Agodini and Dynarski 2001). This literature is reviewed more fully in Glazerman, Levy and Myers, 2002. The US government commissioned a review of youth employment and training programs to determine what had been learned. The experts who participated in that commission found: "Our review of the research on YEDPA [Youth Employment and Demonstration Programs Act] shows dramatically that control groups created by random assignment yield research findings about employment and training programs that are far less biased than results based on any other method. . . . The fact that some studies successfully used random assignment suggests that this procedure is feasible and presents no serious technical difficulties in execution. It is evident that if random assignment had consistently been used in YEDPA research, much more would have been learned." Betsey et al 1985, p. 18). This does not mean that random assignment studies are a panacea, nor that they should completely replace other studies. Random assignment studies should only be used when the questions being addressed are amenable to this research approach. In addition, researchers must follow well-established standards for assuring that assignment is random and that results are not biased by attrition. Sometimes random assignment studies sacrifice generalizability in order to assure that they can properly attribute impacts to an intervention, but this should then be compensated by replicating such studies in different contexts and accumulating a broader body of knowledge about the intervention. Finally, the use of random assignment studies to analyze complex social policies is still developing and researchers need to pay careful attention to the underlying mechanisms and models of behavior that are being tested so as to be sure that the method is applied where it is appropriate. Well-done random assignment studies are an essential tool for building knowledge on "what works" in social policy and greater investment in such studies is needed. |
As demonstrated below, such random assignment studies are feasible. However, they must be applied where they are appropriate. Random assignment studies are most effective at improving the “internal validity” of a study, that is, assuring that the measured changes among beneficiaries can be attributed to the program and not to other potential contributing factors. They are good at answering questions regarding whether or not a program in a particular context had an impact. They are less effective at “external validity”, that is, at proving that the program would have the same impact in other places or times. Nevertheless, by replicating random assignment studies in different contexts and by carefully documenting the conditions under which programs are started and implemented, a body of knowledge regarding external validity can be established to complement the findings from particular projects.
Random assignment studies also require advance planning and careful attention to the process of random assignment and attrition, as well as time and money (See, for example, Victora et al 2004 and Altman et al 2001). As a result, it is quite easy to neglect impact evaluations or do poor ones, and the number of well-done studies remains limited. Part of the challenge for addressing the Evaluation Gap is to do better studies, while another part is to improve our methods for addressing these limitations.
Too few impact evaluations meet the quality test
Demand for the knowledge that good quality impact evaluations provide is apparent every time a policy advisor or agency staff member commissions a literature review. However, many of these reviews refer to the conclusions of reports and studies without regard to their methodological rigor. When quality is taken into account, such reviews frequently discover that most studies are flawed and that only a few of them actually provide reliable information on impact.
This is the case with studies of community health insurance cited earlier. One review of 127 studies found that only 2 cases that studied the impact of community health insurance on health service utilization had internal validity (See Figure 2). That is, only 2 cases could measure the net impact of the program after accounting for potentially competing explanations. Another review on this topic found that only 5 out of 43 studies that considered the impact of community health insurance on mobilizing funds and improving financial protection for members were able to use statistical controls to support their findings (Ekman 2004).
Additional examples include:
- The impact of payment mechanisms on health care providers was the subject of a Cochrane Review. After searching 17 bibliographic databases, including ISI, Econlit, and MEDLINE, the review found only four studies that could draw valid conclusions (Gosden et al 2004).
- The "What Works" Working Group reviewed 56 public health interventions that were nominated by leading international experts as examples of major successes. Of these 12 were excluded because they were too new to be properly evaluated or were small scale. But 27 were excluded because the impact of the public health interventions could not be documented (Levine et al 2004).
The very small number of good quality impact evaluations being undertaken, in contrast to the large demand, demonstrates that there is serious underinvestment in these studies. This is not to imply that impact evaluation should be done to the exclusion or detriment of process, operational and other kinds of evaluation that answer different kinds of questions. These other kinds of studies are extremely important for tracking inputs, improving implementation, and making programs more efficient at delivering outputs (World Bank 2004, Scott 2005). But those studies do not ultimately answer the question of whether these better implemented programs are having a positive impact. This is why more systematic production of good quality impact evaluations on questions of enduring importance are needed in order to inform policy design and resource allocation.