Recommended
The new year is generally a time for introspection and self-improvement, but in the spirit of Calvin and Hobbes, I’ve got a resolution I’d like developing country governments, donors, and researchers to commit to: invest in, and use, national data collection systems.
Responding to COVID-19 was difficult. A few countries responded to the virus and protected the economically vulnerable very well—Taiwan being a shining example—and many did extremely poorly. But many just don’t know how well they did, or how bad the virus or the economic consequences were, and may not for many years. Even worse, during the pandemic, when a strong foundation of knowledge (who to target, which sectors to support, where people lived and worked) was essential for the design of policy, including urgent social protection, many of the poorest countries were flying blind.
We are in this position because of massive and sustained underinvestment in national, regular, and institutionalized data collection and presentation systems. Though developing countries are the subject of a fair amount of academic study (in some places to the point of absurdity, as with Busia, Kenya), these are small, ad-hoc, and driven more by researcher convenience and academic novelty than the state’s requirement of systematic, comparable and actionable evidence applicable to the full breadth of its domain. To get a sense of how bad the data deficit, I looked at the metadata of the World Bank’s Country Policy and Institutional Assessment (CPIA) for low and lower-middle income countries in 2020, which provides a detailed list of the most recent national data sets for each country assessed. The picture is grim.
The very basics are too often out of date
Figure 1: Basic data such as GDP and Population Censuses often require urgent updating
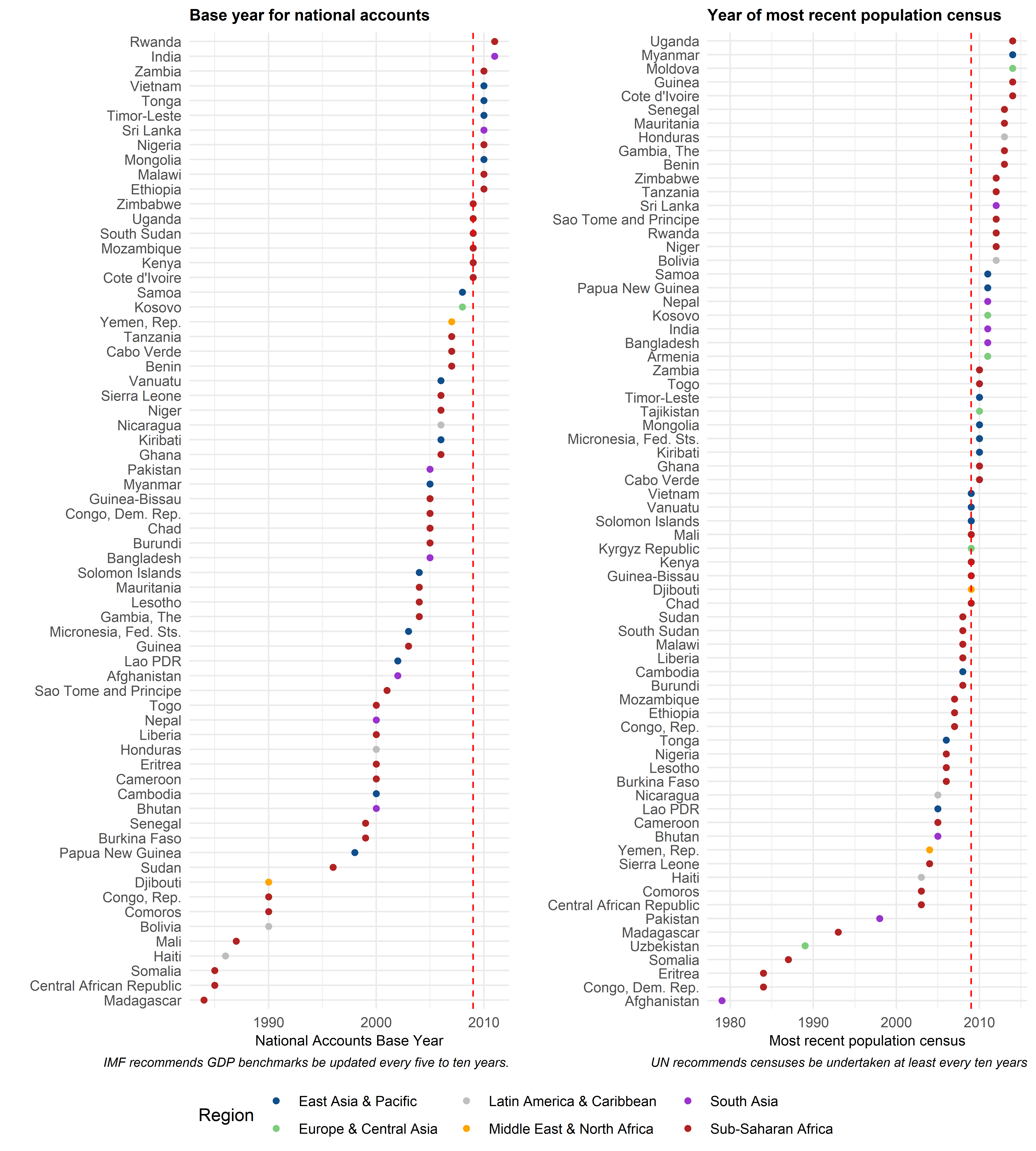
Let’s start with the bare minimum. It is not a new concern to note that GDP data in developing countries are weak—Morten Jerven’s Poor Numbers is, after all, almost a decade old now. It is, however, startling how few countries manage to meet even the looser IMF recommendation of rebasing GDP every decade. Indeed, the situation is a little worse even than this: among LICs and LMICs covered, 17 use the System of National Accounts methodology from when Hey Jude topped the year-end Billboard Hot 100—1968—and a further 45 use the 1993 system (Whitney, if you’re asking). This matters particularly for developing countries: the process of development typically involves substantial economic reorganization. With such long intervals between GDP rebasing surveys, our knowledge about the basic economic structure of a country becomes outdated. Though census data are less out of date, there remain a subset of countries which are simply unlikely to know where, or how many, people are living (which also calls into question how samples for any other surveys are drawn). Household survey data are typically more recent, which allows for better policymaking, though not all of these household surveys included income or expenditure measures—and it is very likely that one of the impacts of Covid-19 has been to make these surveys much more difficult to conduct and keep up to date.
Figure 2: Survey data is usually more recent, but still wildly out-of-date in some countries
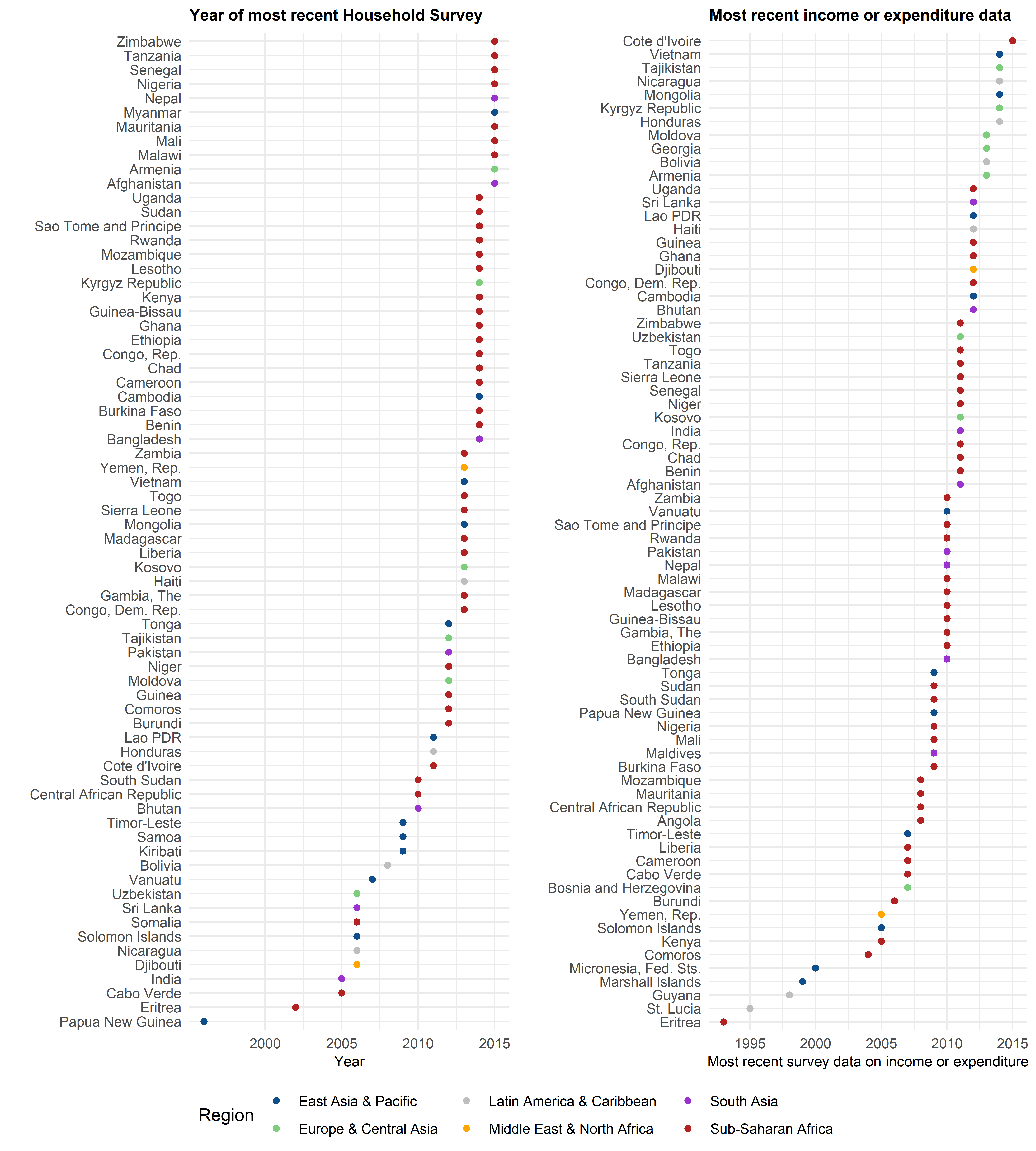
In short, it is difficult to see how, when decisions need to be taken quickly and on the basis of data to hand, policy makers in most developing countries could be expected to act to support either the parts of the economy or the regions or households that most need support. Even in non-pandemic times, this is akin to driving with only one headlamp working and a mapbook missing several pages.
Sectoral data are equally patchy
Figure 3: The latest sectoral survey – where available at all – is often more than ten years old
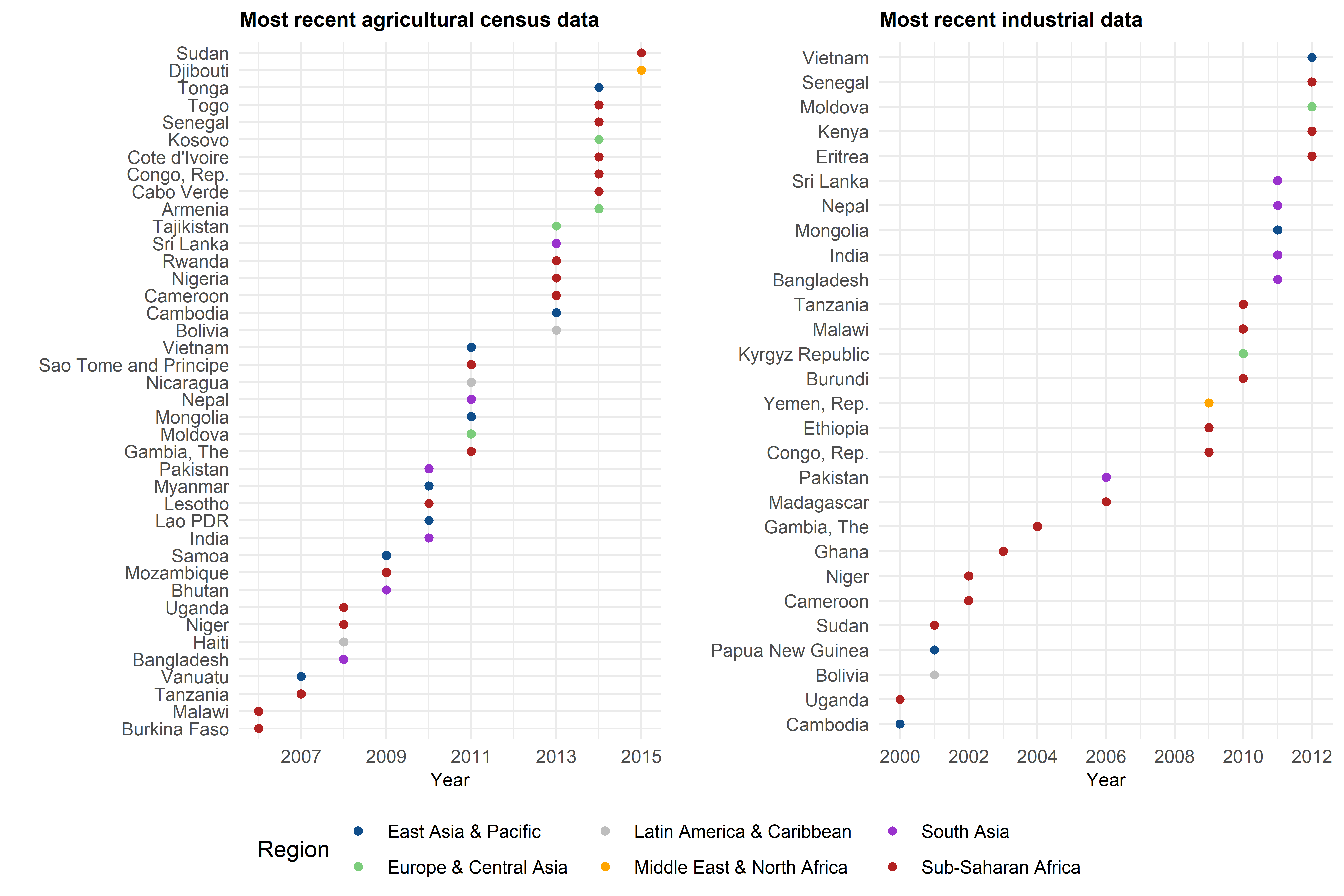
Sectoral data, too, is weak. While GDP rebasing—when it happens—provides information on the structure of the economy, crafting policies that support productivity, design basic support, and motivate research requires much more detail. Agricultural and industrial censuses provide this. They do not just look at the value of production in these sectors, but which specific items are being produced, where, and by whom using which inputs and in what kind of establishment. In countries where they are conducted and kept up to date they form the basis of agricultural and industrial policy; indeed it’s virtually impossible to know what the right policy approach is if we don’t know which crops are being planted, and on what kinds of land. Even if the strategy relies on providing information (as with digital agriculture), it’s difficult to know how Malawi, where the most recent agricultural census was 15 years ago, can decide what information is needed or who to target.
What can we do?
The problem is not primarily a constraint of expertise in how to run surveys: virtually every country in the world has the capacity to run, or host, major household surveys or GDP surveys. Nor is it primarily a problem of fragility—relatively few countries are so war-torn that a proper survey cannot be undertaken. The solution is unlikely to be a new method or a technology.
Instead implementing existing processes and guidance more regularly would materially improve matters. Simply investing more and reallocating some resources from lower-return activities to basic data collection, in partnership with national institutions (which themselves require investment) that have a stake in their production and use, will make a difference. This is easier said than done: data collection and governance are usually deprioritized—in both developed and developing countries—in times of fiscal difficulty, as virtually every country in the world now faces. But one step in the process will be conceptual: moving from thinking about the basic data infrastructure as being a competitor to other sectors to considering it an input into investing in those sectors effectively. To do so, you need information, and that information needs to be kept up-to-date. An adequately funded, competently staffed statistical institution with a clear multi-year programme of work is not ruinously expensive, and can help increase efficiency elsewhere in government spending.
Even this is unlikely to be enough in isolation. Data are not the only input into good policy—political will and decision-making structures and incentives are probably much more important and may well be part of the reason why data generation is so systematically neglected. Political leaders prefer statistics that are malleable or produced only when convenient, and in many cases may be happy to tolerate the continued dysfunction of their statistical agencies (if not actively commission it). Donors and outsiders can and should use pressure and funding to make this harder, though it may be in large part outside of their control. At the very least, by making it more affordable, and providing adequate financial and technical support they can remove “cover” for the intentional neglect of national data collection and reporting institutions.
Action to improve matters is urgent and has been for some time. A 2014 CGD Working Group made similar recommendations in more detail. Looking at the lack of progress in light of a pandemic where data disparities are as sharp as economic and vaccine inequalities is sobering and should shame both donors and national governments.
Michael Pisa and Mark Plant gave excellent comments on an earlier version of this blog.
This blog was updated on 13/1/21 to remove five countries which use chained national accounts data from the GDP base year panel of Figure 1. The five countries removed were: Armenia, Kyrgyz Republic, Moldova, Tajikistan and Uzbekistan.
Topics
DISCLAIMER & PERMISSIONS
CGD's publications reflect the views of the authors, drawing on prior research and experience in their areas of expertise. CGD is a nonpartisan, independent organization and does not take institutional positions. You may use and disseminate CGD's publications under these conditions.



