Recommended

Funders and practitioners in global development are starting to look past the AI hype and take evaluation seriously. But the field is young, and a core challenge remains: there’s little agreement on what “good evaluation” looks like for AI-enabled interventions. Consider a generative AI chatbot for nutrition coaching: before asking if it improves outcomes, developers need to know if it’s safe, scientifically sound, and regularly used. It’s tough to expect impact without these basics.
Earlier this year, several authors proposed a framework for evaluating social sector AI products, but consensus is still lacking—on both how to assess early capabilities and what resources are required. Without shared standards, it is difficult to compare products and service providers. To plug this gap and raise the quality of AI evaluations across global development, we—a group of researchers, evaluators, donors, and builders—propose four key investments to advance our sector:
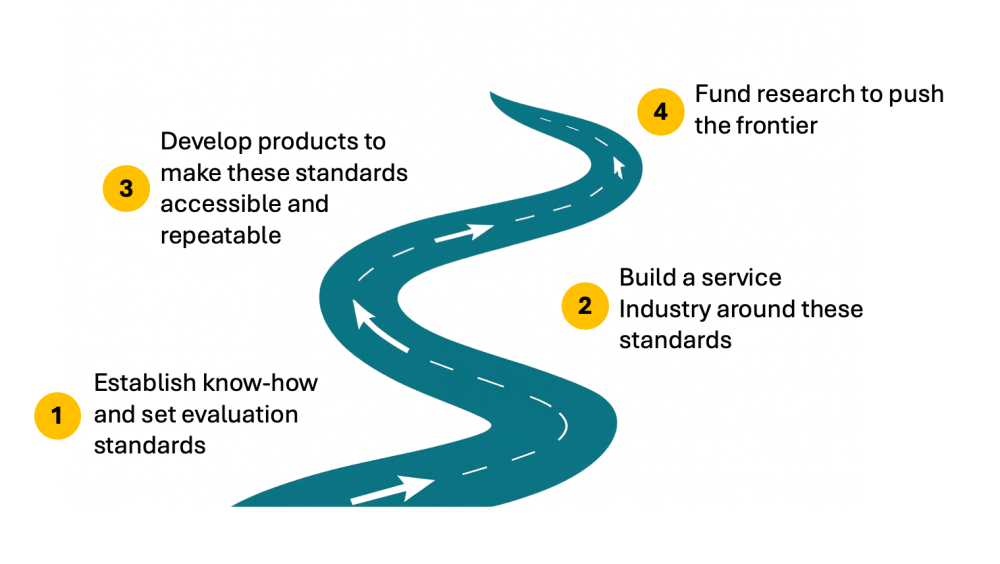
Investment 1: Establish Know-How and Set Evaluation Standards
The development sector has built a rich body of evaluation knowledge. Some fields try to establish the causal links between interventions and outcomes; others focus on program fidelity. Shared standards have emerged—randomized evaluations are the gold standard for impact, while classroom observation is widely used to assess fidelity in education. These standards are supported by extensive literature, playbooks, courses, and tools. Yet they don’t address the new evaluation techniques unique to AI product performance, which are often unfamiliar to development practitioners. Take the AI nutrition coach: developers may want it to cite only a predefined set of scientific sources. Measuring faithfulness requires techniques common in tech but new to global development—like checking keyword overlap or testing whether claims are correctly attributed.
Because these techniques are new and standards for the social sector are lacking, donors—from private philanthropies to bilateral agencies—are pushing to consolidate technical know-how and establish common yardsticks. One solution is sector-specific benchmarks in education and health, which give developers a shared reference point to measure performance on subjects like pedagogy or medical emergency detection. The Agency Fund, a “funder-doer,” has also made an early contribution by creating an AI Evaluation Playbook, drawing on lessons from the AI for Global Development Accelerator. The accelerator, run in collaboration with OpenAI and CGD, supports eight nonprofits with funding and technical assistance to build generative AI products—and serves as a testbed for these evaluation methods.
While playbooks are a strong foundation, they need to undergo a process of debate, iteration, and broader buy-in before wider industry adoption. This includes pulling in ideas from other organizations and accelerators to shape a shared sense of what “good” looks like. AI evaluation is part art, part science—driven as much by trade-offs and assumptions as by technical methods. To move this process forward, CGD will convene global experts in late 2025, including from low- and middle-income countries (LMICs), to review playbooks, resolve ambiguities, and publish a resource the field can align on. More efforts will follow in areas like mental health, education, and agriculture—but this is a first step.
Investment 2: Build a Services Industry around these Standards
Beyond agreeing on evaluation standards and sharing technical know-how, many implementers will also need hands-on support to put these techniques into practice. In reality, most designers of AI-powered social services will require help to:
- Establish metrics to measure model and product performance
- Catch and correct aberrant large language model (LLM) behaviour
- Deploy observability systems to automatically monitor AI services—tracking safety violations, unintended consequences, and performance drift; and
- Adopt modern engineering practices—like building robust data pipelines and iterative A/B testing—to continuously evaluate and improve products
- Publish and publicly share their results in a way that’s useful to the ecosystem
These activities differ from the conventional monitoring and evaluation (M&E) practices in global development. Social sector organizations have been slow to modernize their M&E infrastructure, constrained by costly commercial software solutions and the difficulty of hiring and retaining engineering talent. Large-scale nonprofit accelerators run by Google, Meta, and the Agency Fund (with OpenAI and CGD) are exposing these pain points, but more needs to be done outside of accelerators.
The social sector needs an ecosystem of consultants, research partners, and service providers to build AI product management systems similar to those in the tech sector. Some efforts are already underway: Project Tech4dev and IDinsight offer fractional technical talent programs to support data warehouses and product metrics dashboards, while organizations like Tattle, Humane Intelligence, and Karya can create evaluation datasets and tools for red-teaming. Donors like the Gates Foundation and Omidyar Network are beginning to invest in an evaluation services ecosystem—but many more will need to follow.
Investment 3: Develop Products to Make these Standards Accessible and Repeatable
While standards and services can build capacity and establish initial know-how, to achieve high quality evaluations at scale we need open source software platforms that automate the most time intensive tasks for nonprofits and governments.
The Agency Fund, Project Tech4dev, and IDinsight are beginning to tackle this tooling challenge, along with organizations like Audere and Tattle. Agency Fund and IDinsight recently co-developed Evidential, a platform that helps organizations automate A/B tests, multi-arm bandits, and other experiments in real time—with minimal need for a dedicated data science team.
Project Tech4dev is building a new open-source platform for model evaluation, integrating tools for chatbot version control, performance monitoring, and sentiment analysis of conversation flows—providing a reference architecture for high-quality evaluation in social service delivery. In collaboration with Agency Fund, it will support voice models, important for low-literacy populations, and include metrics tailored to low-resource languages. The platform will also be compatible with chatbot builders like Gooey.AI, Glific, Dimagi Chat Studio, and turn.io, making it easier to embed rigorous evaluation workflows across the ecosystem.
Investment 4: Fund Research to Push the Frontier
Some evaluation techniques are already well established and should be codified into industry standards, services, and products. But many open questions demand new research. One challenge is speed: AI products evolve so quickly that they often outpace researchers’ ability to fully assess the impact of those changes. Can we accelerate impact evaluations with credible surrogates? Or design data pipelines—using remote sensing or in-app data—that enable continuous evaluation, with outcomes observable in real time, and without lengthy surveys?
Other questions loom large– particularly how to advance progress on models for low-resource languages. New research to evaluate these models is critical for social impact. Investments by the Gates Foundation and Google.org in groups like Masakhane are valuable, but the need is far greater. We won’t attempt to lay out a full research agenda here, but progress on even a few of these fronts would significantly advance the field. This research should work in conjunction with the other three investments, with mature research results feeding into playbooks, services, and products.
Put it All Together
Strong evaluation of social sector AI won’t materialize by itself. The private sector already has standards, services, products, and research to lean on; global development requires concerted investment and orchestration across these domains. With the field still young, we have a rare opportunity to shape it and align around strong, shared standards.
Topics
DISCLAIMER & PERMISSIONS
CGD's publications reflect the views of the authors, drawing on prior research and experience in their areas of expertise. CGD is a nonpartisan, independent organization and does not take institutional positions. You may use and disseminate CGD's publications under these conditions.