Recommended


How do you evaluate a development intervention based on generative AI, like a tutoring tool or a chatbot to provide advice to farmers?
A technical lead might say that evaluating a generative AI tool means getting the model to perform well, putting safeguards in place, and shipping it. An economist might think that the work is done after an impact evaluation shows progress on development outcomes. Neither view alone captures the full breadth of what evaluating generative AI requires. As technological change accelerates, the model, the product, and the user keep evolving; development interventions need to keep adapting to that change. Traditional, one-off evaluations miss the opportunity to enable such continual improvement, but a new approach can drive better intervention design over time.
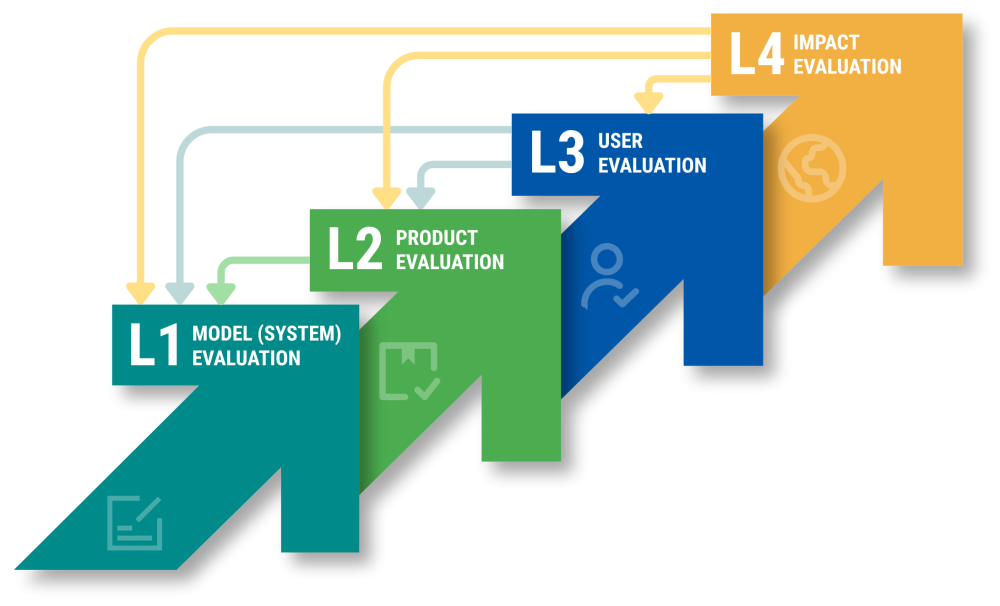
The Generative AI Evaluation Playbook lays out a four-level framework for evaluating generative AI interventions through a process of continuous assessment. The Playbook separates evaluation into four connected levels: how the model performs; whether the product engages users; whether users change behaviors; and whether development outcomes improve. The four levels build on each other, helping teams craft effective generative AI applications that keep getting better. The Playbook is published by The Agency Fund, CGD, and IDinsight, and we’ve been fortunate to work with a number of implementers to test-drive the framework. Here’s how one, Digital Green’s FarmerChat, illustrates continuous improvement.
Source: Generative AI Evaluation Playbook
The Playbook’s four-level evaluation framework in practice: FarmerChat
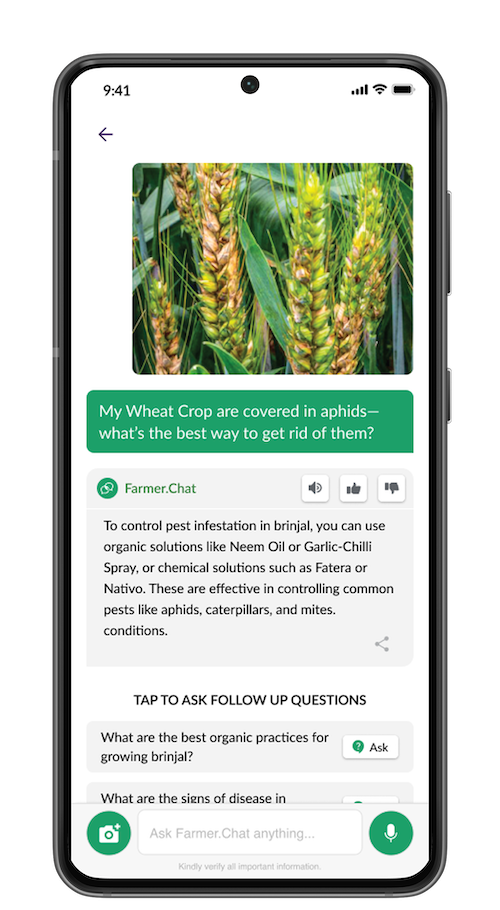
Built as an AI advisory service for smallholder farmers, FarmerChat supports voice, text, and image exchanges to deliver advice on topics like crop choice, planting, livestock, fertilizer use, and pest management to around 1.6 million farmers across six countries. FarmerChat has logged 16 million interactions, providing ample data to support the Playbook’s four-level approach.
Level 1, model evaluation, asks whether the AI system performs reliably for its intended use. This level of the Playbook has a few core steps: define a rubric of qualities the system must show, construct a curated “Golden Dataset” of realistic questions and ideal responses, and score the model's outputs against that dataset. This is not a one-time process, but a running loop.
Digital Green has fine-tuned its tool to improve performance, which remains a work in progress: in one crop-advisory benchmark, fine-tuning raised average recall—correct responses the model retrieved—from 0.26 to above 0.5. There has been meaningful progress on some crops, but less for others, which is a reminder that model evaluation is not a pass/fail exercise: the benchmark itself has to keep expanding across crops, geographies, languages, and high-stakes advisory topics. The path forward is to keep up the process, with a focus on those crops that need uplift most: domain experts reviewing real-world chat logs, feeding ratings back, and raising response quality, feedback loop by feedback loop.
Level 2, product evaluation, asks whether the overall product engages and retains users. A great model is useless without user adoption of the product it serves. In practice, this means tracking how users move through the app, identifying where they drop off or get stuck, and A/B testing improvements.
Gauging the success of a product version takes time, which creates tension between evaluation and iteration. Digital Green had to adjust its development loop to learn where to iterate fast and where to evaluate carefully. Disciplined versioning, making sure to test one change at a time, was needed for improvement: removing lengthy registration requirements improved sign-up completion by 21 percent. Users who engaged with visual stories averaged longer sessions, which is a useful signal, even if it could also reflect confusion rather than deepening engagement. Data charges are a key constraint for poorer farmers: in one telco partnership, waiving data costs for the use of FarmerChat (“zero-rating”) was associated with a 31 percent increase in queries. These gains are driven by the same process: identify a drop-off in engagement, hypothesize a cause, test a fix, and repeat.
Level 3, user evaluation, asks whether the product is changing what users think, feel, and do. The answers go beyond informing how to retain existing users, to learning how to broaden the user base and serving them better by building trust and influencing behavior. The Playbook proposes combining on-platform signals apparent through interactions such as belief updating, trust, or intent to act with off-platform research like surveys, interviews, and behavioral metrics that can reveal key user dynamics. That can help understand why potential users stay on the sidelines.
Women farmers are a key constituency for Digital Green but have been harder to win over: interviews point to low trust as the driver of their caution in a male-dominated sector. The cost per install for women is higher than for men, but the real adoption lever has been product redesign—signaling credibility and relevance to women—not higher spend. Once reached, Kenyan women posted elevated net promoter scores—likelihood to recommend the app—in a survey, suggesting strong satisfaction with the product. Reaching women farmers increases overall adoption, but pushing their share above the current 35 percent requires further evaluation of women users’ needs.
Level 4, impact evaluation, asks whether the product improves the development outcomes that are the ultimate objective. Clear benefits need to justify time-on-app, so that virtual interactions feed through to positive change in the real world. Implementation lies in the rigorous causal toolkit of development economics: a defined counterfactual, a methodology like a randomized controlled trial (RCT), version control on the product, and objective outcomes.
Digital Green is working toward this level by running RCTs with the International Food Policy Research Institute (IFPRI) and the University of Bordeaux. What gave the team confidence to commit was a strong usage signal: in a Kenya user survey, around seven out of ten FarmerChat users reported taking practical action on their farm based on its advice. Such self-reported Level 3 evidence is no substitute for an RCT, but it can help justify the cost of one.
Although it should provide conclusive evidence of FarmerChat’s effectiveness at the time of evaluation, a successful impact evaluation is no end state for product teams. Positive results could encourage expansion to new geographies that require new optimizations across levels. Heterogeneity in outcomes can prompt action to enhance the system for groups it underdelivers for. Even a lack of impact invites a hard but equally productive question: at which level does the theory of change break down? We hope that the RCTs deliver encouraging results for FarmerChat users. Whatever the findings, they will become part of the next evaluation loop; level by level, evaluation generates the evidence to drive continual improvement.
Organizations interested or already engaged in building GenAI tools for development can consult the Generative AI Evaluation Playbook, sign up for AI Initiative updates, watch a recent session outlining the Playbook and Digital Green’s use of AI evals, or read the Playbook’s policy brief.
Tim Ohlenburg is a research fellow with CGD's AI Initiative.
Rikin Gandhi is the CEO of Digital Green.
Topics
DISCLAIMER & PERMISSIONS
CGD's publications reflect the views of the authors, drawing on prior research and experience in their areas of expertise. CGD is a nonpartisan, independent organization and does not take institutional positions. You may use and disseminate CGD's publications under these conditions.
Thumbnail image by: Digital Green



